
lunes, 07 de septiembre de 2009 a las 16:42hs por Dario Krapp
En más de una ocasión nos fue necesario importar datos en formato CSV a una tabla en nuestro servidor de base de datos SQL Server, después de esta última vez me pareció una buena idea hacer un muy breve comentario de una de las posibilidades disponibles, así es que presento al comando BULK INSERT, el cual permite llevar a cabo esta operación.
Antes que nada debemos suponer que poseemos la siguiente tabla:
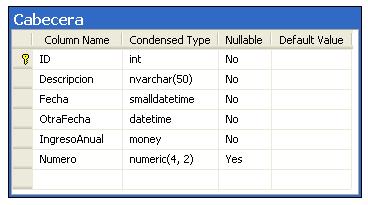
1,Cabecera1,20001211,20001211 22:10:30,41422.66, 22.22 2,Cabecera2,20001212,20001212 22:10:32,1234567.123456, 22.4444
Y la clara intención de copiar la información desde el archivo CSV hacia la tabla en cuestión. Deberemos entonces utilizar el siguiente comando:
BULK INSERT
Cabecera
FROM
'C:\....\archivo.csv'
WITH (
FIELDTERMINATOR= ',',
ROWTERMINATOR = '\n'
);
Donde hemos especificado origen (el path al archivo CSV) destino (la tabla Cabecera) y los separadores de filas y columnas en los argumentos ROWTERMINATOR y FIELDTERMINATOR.
El resultado de la operación generará el siguiente resultado:

En otros tipos de errores, como por ejemplo, violación de la constraint UNIQUE, la importación fallará, cabe mencionar que para el caso particular de las constraints CHECK y FOREIGN KEY, las mismas serán por defecto omitidas, al menos que se utilice el parámetro CHECK_CONSTRAINTS en la sentencia BULK INSERT para especificar lo contrario.
El comando BULK INSERT posee además de los pocos parámetros que hemos visto una diversa cantidad de los mismos, como por ejemplo FIRSTROW y LASTROW que permite especificar la fila inicial y final de copia, FIRE_TRIGGERS que permite indicar si se dispararán los triggers de las tablas durante la importación de datos, KEEPIDENTITY que permite especificar de qué manera se manejarán la columnas identity durante la importación y KEEPNULLS que indica si las columnas vacías deberán conservar el valor NULL.
Dejo para quien este interesado el siguiente link donde podrán obtener más información del comando, de todos los argumentos disponibles (que son muchos más que los que hemos mencionado) y de su uso:
http://technet.microsoft.com/es-es/library/ms188365.aspx
Espero que esta pequeña contribución haya servido para quienes no conocieran la existencia de este comando.
Categoria SQL Server | Etiquetas: BULK INSERT

Buenas,
Gracias por facilitar información sobre la sentencia BULK INSERT aunque me surge la siguiente duda:
Imagina que mi tabla no tiene la misma estructura que el fichero del que quiero realizar la importación, por ejemplo que tenga muchos menos campos y en otro orden.
¿Cómo podría especificarle al BULK INSERT qué columna del fichero corresponde a qué campo de la tabla en la base de datos?
Un saludo y muchas gracias de antemano
Hola Rikku,
La sentencia BULK INSERT aceptará un argumento llamado FORMATFILE en el cual podrás especificar el path a un archivo, en dicho archivo podrás definir el mapeo entre el origen y el destino.
Podés encontrar la explicación de este argumento, junto con todos los que acepta la sentencia en:
http://msdn.microsoft.com/en-us/library/ms188365.aspx
Por otra parte, para crear este archivo podés emplear la utilidad bcp desde la linea de comandos, te dejo otro link donde te explica como utilizarla, ya que la misma acepta una infinidad de argumentos y opciones:
http://msdn.microsoft.com/en-us/library/ms162802.aspx
Sdls
Darío
[…] Importación de archivos CSV con el comando Bulk Insert […]
Hola muy buena la info, tengo una consulta en mi archivo csv tengo un campo descripción el cual posee el siguiente texto «luces, lamparas». Forman parte de la misma columna pero como en el medio tiene una coma me lo transforma en 2 columnas. Como puedo salvar este problemas
Muchas gracias!
Hola, Pedro.
Podrías reemplazar el separador de campo por otro valor, por ejemplo por «|», reemplazando las comas del CSV y el valor de FIELDTERMINATOR por este caracter.
Suerte!
Excelente y muy claro!
Cómo se utiliza o se dice para q importe desde la segunda fila. El txt a cargar tiene cabeceras
FIRSTROW =2
hola, estoy intentando usar el FIRSTROW =2 ya que mi primera fila del txt es mi encabezado y luego vienen los registro, utilizo el FIRSTROW =2 y me omite la pirmera fila (encabezado) y la segunda fila que es mi primer registro por lo que se empieza a cargar la tabla desde el segundo registro, como hago para que salga bien?. esto se debe a que mi primera fila no cumple con los campos de la tabla de los registros entonces no la toma en cuenta a la hora de saltar la fila. Como puedo hacer para que funcione bien lo que quiero?
Hola Carlos.
El FIRSTROW no está pensado para saltear los encabezados (está en la documentación: BULK INSERT (Transact-SQL)). ¿Si no le ponés el FIRSTROW=2 no funciona?
Saludos.
Excelente informacion.. Una duda .. si mi archivo de texto tiene como separadores un espacio en blanco (Tab) la sentencia de FIELDTERMINATOR como seria ?
FIELDTERMINATOR= ‘ ‘ … solo se dejaria un espacio en blanco
Hola Bryan.
Estoy «casi» seguro que funciona con
FIELDTERMINATOR = '\t'.Después comentame si te funcionó.
¡Suerte!
Si sirvió Amigo muchas gracias. Ahora tengo un problema .. tengo un poco mas de un millon de registros y una linea del registro tiene información errónea .. Existe alguna forma de saltarse esa linea y que continué la carga ?
Como hago si son varios archivos de cvs para que se me carguen diariamente automáticamente al sql?
Favor re-acomodar las dimensiones de su página web, el contenido esta perfecto, pero es una molestia para los ojos al leerlo. Agradezco su atención.
Muchas gracias por el aviso Esteban, quedó mal en alguna actualización pero ya lo resolvimos.
Saludos.
Hola, buen dia. Si tengo un CSV delimitado por ; (punto y coma) y dentro del texto de un campo tengo datos como «hola; chau» y no tengo posibilidad de modificar el delimitador de campos, podrìa especificar de alguna forma que lo que està dentro de » » no se debe tomar como tal?
Estoy trabajando con Sql Server 2014 (Vi que para versiones mas nuevas si hay opciones)
Buen dia
Una pregunta,estoy tratando de pasar la ruta del archivo por medio de parametro pero no ha sido posible, saca el error de que el archivo no existe, ejemplo, donde dice from, le coloco »+@ruta+», no me da pasandole la ruta por parametro, como hago?
En ese caso te conviene meter toda la sentencia en una variable y luego ejecutarla con un EXECUTE.
¡Suerte!
Mucha gracias por la información. Tengo una consulta: Si quisiera cargar solamente la primer fila (ya que en esa fila me indica ciertos datos que corresponden a la cantidad de registros del archivo), como puedo hacer para cargar solamente ese registro e ignorar el resto. Aclaro que la primer fila solo tiene 2 campos y el resto 6.
Gracias.
Hola Carina.
Para cargar sólo algunos registros puedes utilizar la opción LASTROW.
¡Suerte!
Hola! Yo intento hacer la carga de mi txt delimitado por | pero al llegar la siguiente fila la carga en la misma columan:(
Hola Verónica.
¿Puede ser que ese archivo no tenga el caracter \n al final de cada fila?
Saludos.
Quiero hacer un bulk insert pero quiero obviar la primera columna ya que es una columna que no esta en el archivo csv alguien que me ayude por favor.
Hola Alejandro.
Para especificar las columnas te recomiendo crear una vista con los campos que necesitás importar, y hacer la importación sobre esa vista.
Suerte!