
lunes, 21 de septiembre de 2009 a las 03:39hs por Dario Krapp
La intención de este artículo es la de comentar una de las nuevas capacidades de SQL Server 2008 que es la posibilidad de crear índices filtrados, pero me parece que es una buena oportunidad para mencionar que son los índices, cual es su objetivo, que tipos de índices existen y dejar para final del artículo este asunto de los índices filtrados.
Comencemos por la idea más básica que es la de preguntarse qué es un índice y para qué sirve, un índice es un mecanismo que permite acceder a un conjunto de datos en forma más eficiente que si no se utilizase dicho mecanismo, considerando a la velocidad de acceso a los datos como el factor de eficiencia que los índices optimizan. En el primer tipo de índice que vamos a comentar la estrategia de optimización consiste en ordenar físicamente los datos de forma que puedan encontrarse más rápidamente, esto significa que en este tipo de índice existirá una o varias columnas que definirán de que manera estará la tabla físicamente ordenada.
Esta idea no es nueva, para quienes hayan programado alguna vez en cualquier lenguaje sabrán que si debemos buscar un valor en un vector ordenado, podremos utilizar algunas técnicas como por ejemplo la búsqueda binaria que permitirán encontrar los datos buscados en orden logarítmico a diferencia del inmejorable orden lineal cuando los valores dentro del vector están desordenados. Para quien nunca haya programado podrá recordar un diccionario, en un diccionario un usuario busca una definición (datos) a partir de una clave (palabra a buscar) y el hecho de que los datos estén ordenados por la clave (o sea las definiciones por las palabras) permitirá que el usuario no tenga que recorrer todas las palabras del diccionario hasta encontrar la palabra deseada. De forma similar dentro de la estructura de tablas del SQL Server el hecho que los datos se encuentren ordenados físicamente por la clave permitirá un acceso más rápido a los mismos. No estará quien se pregunte qué sucederá cuando se inserte un nuevo registro con la performance, y no hay dudas que será menos eficiente que si los datos estuviesen desordenados, pero no hay que olvidar que lo que se desea es eficiencia en las operaciones de búsquedas, que son las que se realizan con mayor frecuencia.
La forma más sencilla de ver la diferencia que puede provocar un índice de este tipo es crear una tabla simple en nuestro motor de base de datos SQL Server y ver el plan de ejecución en ambos casos (con y sin el índice), comencemos creando la tabla y agregando algunos valores:
CREATE TABLE [dbo].[Datos1]( [ID] [int] NOT NULL, [Numero] [int]NOT NULL, [Descripcion] [nvarchar](50) NOT NULL, )
INSERT INTO Datos1 ([ID],[Numero],[Descripcion]) VALUES (1,1,'D1') INSERT INTO Datos1 ([ID],[Numero],[Descripcion]) VALUES (2,2,'D2') INSERT INTO Datos1 ([ID],[Numero],[Descripcion]) VALUES (3,3,'D3') INSERT INTO Datos1 ([ID],[Numero],[Descripcion]) VALUES (4,4,'D4')
Luego iniciaremos una búsqueda y veremos el plan de ejecución. El plan de ejecución mostrará de qué manera el query optimizer intentará acceder a los datos durante una consulta, (El query optimizer es el encargado de diseñar la estrategia del acceso a los datos).
Existen varias maneras de ver el plan de ejecución, utilizaremos en estos ejemplos la forma grafica.
Luego de haber ejecutado el script previo deberemos escribir lo siguiente en un query analizer:
SELECT [ID], [Numero], [Descripcion] FROM Datos1 WHERE ID=1
Y luego presionar CTRL+L. Se obtendrá un resultado similar a lo siguiente:
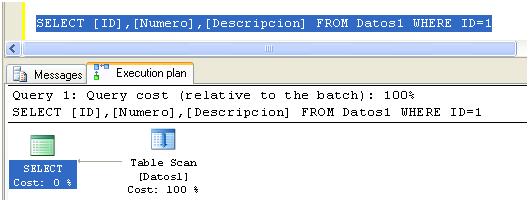
Los planes de ejecución en formato gráfico deben leerse de izquierda a derecha y de arriba hacia abajo, y aunque pueden ser extremadamente largos y complejos de leer, en nuestro caso podemos ver el mismo está compuesto por solamente dos iconos y una flecha que los une a ambos. Cada icono representará una operación y la flecha simbolizará el movimiento de datos entre las dos operaciones, indicándonos que la operación “Table Scan” ha tomado los datos que la operación SELECT procesará, en realidad la operación SELECT no ha hecho nada en este caso. Este diagrama nos indica que está haciendo internamente el motor de base de datos.
Una operación “Table Scan” nos está indicando que el motor ha necesitado recorrer secuencialmente la tabla Datos1 para poder encontrar los registros que cumplan con la condición pedida.
La operación “Table Scan” es equivalente a tener un diccionario desordenado donde es necesario recorrerlo secuencialmente hasta encontrar la palabra que deseamos buscar, pero además la palabra puede existir más de una vez, así que siempre deberemos recorrerlo hasta la última palabra para asegurarnos que hemos encontrado todas las definiciones. Cuando no hay índices creados la performance de las búsquedas quedan gravemente comprometidas.
En contraposición crearemos un índice y veremos que cambios se producen en el plan de ejecución, ejecutaremos la siguiente línea de código:
CREATE CLUSTERED INDEX IX_1 ON [dbo].[Datos1] (ID)
Donde hemos indicado la creación de un índice por la columna «ID»,(la palabra CLUSTERED indicará que la tabla se ordernenará físicamente por el índice solicitado, luego veremos que existe otro tipo de índices que no impone tal condición.)
Si volvemos a ejecutar la consulta anterior, el plan de ejecución tomará el siguiente formato:
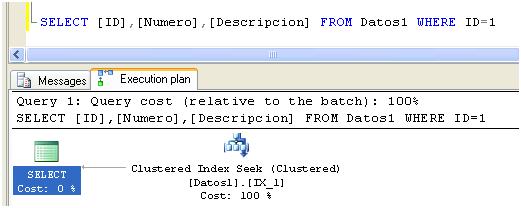
Indicando que en este caso la búsqueda de datos está utilizando el índice IX_1, de manera que el motor ya no debe recorrer toda la tabla para encontrar los registros pedidos.
Podemos ahora preguntarnos que pasaría si además es necesario realizar búsquedas por otro campo, supongamos por el campo «Numero», en este caso no podremos reordenar la tabla físicamente por «Numero», ya que al hacer esto perderíamos el orden físico que ya habíamos establecido por el campo «ID», es claro que el orden físico puede establecerse solo para una clave (ya sea compuesta por un solo o varios campos). Para estos casos existen otro tipo de índices conocidos como índices non-clustered, ya que no modifican el orden físico de los registros en la tabla original, estos índices guardarán en otra estructura una copia de los valores involucrados en la clave y un puntero al registro original de la tabla. Para probar lo antes comentado ejecutaremos el siguiente comando:
CREATE INDEX IX_2 ON [dbo].[Datos1] (Numero)
Y luego veremos el plan de la siguiente búsqueda:
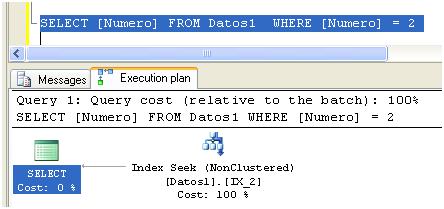
Donde puede verse que el query optimizer ha decidido utilizar el nuevo índice IX_2.
Habrá seguramente quien se haya percatado que en este último query solo estamos incluyendo a la columna «Numero» y se pregunte el por qué de esta decisión?, y más aun, habrá quien pareciéndole extraño realizará la misma búsqueda pero esta vez con todos los campos (al menos eso espero). Si es así, quien realice esta prueba descubrirá algo pertubador, y es que el query optimizer habrá decidió utilizar el índice IX_1, y no IX_2, pero por que? podrán preguntarse y la respuesta es la siguiente:
Como comentamos previamente los índices non-clustered guardan una copia de las claves y un puntero al registro original, de esta manera cuando hemos buscado solamente por «Numero» el índice IX_2 es capaz de devolver la información solicitada ya que posee el valor de la columna «Numero», pero cuando hemos pedido otros datos como «ID» y «Descripcion» que no existen en IX_2 el query optimizer ha decidido que es menos costoso recorrer la tabla por IX_1 para devolver los datos que IX_2 no posee. Cuando un índice non-clustered cubre todos los datos solicitados en la consulta se dice que es un covered-index, el caso contrario no será un covered-index y el query optimizer deberá buscar alguna estrategia para obtener los datos faltantes, obviamente los clustered index son siempre covered index, ya que poseen el registro completo.
El query optimizer puede utilizar otras estrategias para obtener los datos faltantes como veremos a continuación. Si ejecutamos el siguiente código:
DELETE FROM Datos1 DECLARE @C int =1 WHILE @C < 10000 BEGIN INSERT INTO Datos1 ([ID],[Numero],[Descripcion]) VALUES (@C,@C + 1,'D1' + cast(@C as nvarchar(10))) SET @C+=1 END
Donde solamente hemos agregado más datos y volvemos a ejecutar la consulta anterior veremos lo siguiente:
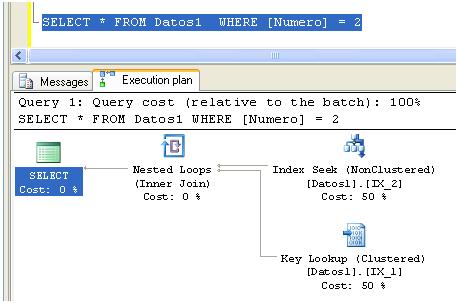
Ahora el query optimizer ha utilizado nuestro índice IX_2 pero para recuperar los datos faltantes a requerido efectuar una operación de Key Lookup extra utilizando el índice IX_1, para finalmente unir los datos en la operación Nested Loops. Si creamos un nuevo índice que cubra todos los datos pedidos de la siguiente forma:
CREATE INDEX IX_3 ON [dbo].[Datos1] (Numero,ID,Descripcion)
No debería sorprendernos el siguiente resultado:
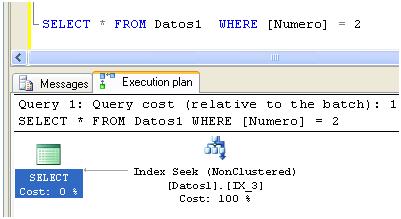
Otra opción para incluir las columnas restantes es utilizar la sentencia INCLUDE de la siguiente forma:
CREATE INDEX IX_3 ON [dbo].[Datos1] (Numero) INCLUDE (Descripcion, ID)
En el segundo caso, las columnas son agregadas al índice pero no forman parte del mismo.
En ambos tipos de índices, clustered o non-clustered existe la posibilidad de definirlos como únicos (unique), un índice único no admite repetición de valores, y permite una mayor optimización en las búsquedas. Las claves primarias de las tablas están compuestas por índices «unique» que pueden ser o no clustered.
En Sql Server 2008 existe además la posibilidad de crear índices filtrados, o sea índices que se aplican solo a un grupo de datos. Para probarlo podemos eliminar los índices IX_2 e IX_3 y crear un nuevo índice IX_4 filtrado, las siguientes líneas de código efectuan estas operaciones:
DROP INDEX IX_2 ON [dbo].[Datos1] DROP INDEX IX_3 ON [dbo].[Datos1] CREATE INDEX IX_4 ON [dbo].[Datos1] (Numero,ID,Descripcion) WHERE Numero < 100
De esta forma el índice IX_4 será aplicable para algunas condiciones solamente, por ejemplo si ejecutamos el siguiente query:
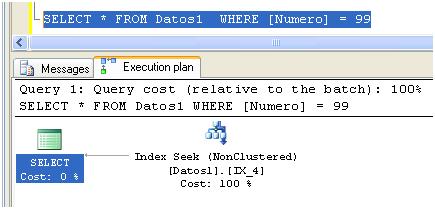
El query optimizer ha decidido emplear IX_4 mientras que en el caso de:
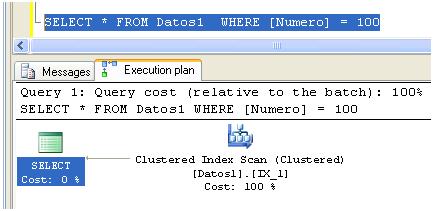
Ha optado por IX_1.
Por último me queda por comentar que existen además de los índices que hemos mencionado (que son los que se utilizan en la mayoría de los casos) los índices full text, los índices XML y los índices espaciales, los cuales espero podamos ver en algún próximo articulo.
Espero como es la costumbre que este articulo haya sido de utilidad y nos vemos en el próximo.
Categoria SQL Server | Etiquetas: SQL Server 2008

Muy buen tema, me ha ayudado mucho a aclarar dudas
Saludos
gracias por tu aporte me ha ayudado a aclarar un poco mis dudas acerca de los indices
Excelente artículo explica los indices de manera sencilla
Muy buen artículo, me has ayudado a tener una mejor visión sobre este tema, saludos!
Muy bien explicado.
Gracias compartir tus conocimientos.
Muy buen aporte y excelente explicacion, espero pronto leer sobre los indices fulltext, XML y espaciales.
Excelente!
Excelente, me ayudado a aclarar algunas dudas que tenia acerca de los indices filtrados.
Gracias por compartir este articulo.
muy buen articulo
Que bueno hombre, en esta vida lo que existe es gente buena